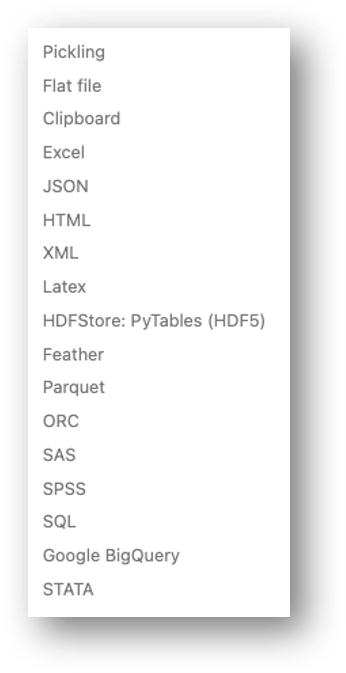
Pandas에서는 다양한 파일 입력을 지원하고 있습니다. 현재 Pandas는 버전 V1.3.0이며, 현 버전 기준으로 Pickling, Flat file, Clipboard, Excel, JSON, Html, Laxtex, HDF, SAS, SPASS, SQL, Google BigQuery, STATA의 파일 포맷을 지원하고 있으며, 이 중에서 일반적으로 가장 많이 사용하고 있는 Excel과 CSV 파일을 읽고 쓰는 방법을 설명합니다.
Pandas로 Excel 파일 읽기: Local File과 Http URL도 지원함
Pandas에서 Excel 파일을 읽기 위해서는 Excel Reader를 설치해야 합니다. Pandas에서 기본적으로 xlrd를 사용하고 있으며 xls포맷만 지원합니다. 만일 xlsx인 엑셀 파일을 읽어야 한다면 openplyxl을 설치해야 합니다. 따라서 xlrd 보다는 최신 포냇의 xlsx까지 지원하는 penplyxl 파일 설치를 추천드립니다. openpyxl 파일만 설치되어 있어도 pandas 엑셀 파일 입출력 동작에는 문제가 없습니다.
$ sudo pip3 install xlrd opnepyxl


xlrd 또는 openpyxl 모듈이 없는 경우 에러 메시지:
Traceback (most recent call last):
File "/Users/kibua20/git/DevDocs/pandas_example/test_dataframe_groupby.py", line 6, in <module>
df = pd.read_excel('./Grade_Sample.xlsx')
File "/usr/local/lib/python3.9/site-packages/pandas/util/_decorators.py", line 299, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 336, in read_excel
io = ExcelFile(io, storage_options=storage_options, engine=engine)
File "/usr/local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 1140, in __init__
self._reader = self._engines[engine](self._io, storage_options=storage_options)
File "/usr/local/lib/python3.9/site-packages/pandas/io/excel/_xlrd.py", line 24, in __init__
import_optional_dependency("xlrd", extra=err_msg)
File "/usr/local/lib/python3.9/site-packages/pandas/compat/_optional.py", line 109, in import_optional_dependency
raise ImportError(msg) from None
ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
Traceback (most recent call last):
File "/Users/kibua20/git/DevDocs/pandas_example/test_dataframe_groupby.py", line 6, in <module>
df = pd.read_excel('./Grade_Sample.xlsx')
File "/usr/local/lib/python3.9/site-packages/pandas/util/_decorators.py", line 299, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 336, in read_excel
io = ExcelFile(io, storage_options=storage_options, engine=engine)
File "/usr/local/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 1111, in __init__
raise ValueError(
ValueError: Your version of xlrd is 2.0.1. In xlrd >= 2.0, only the xls format is supported. Install openpyxl instead.
Panda에서 엑셀 파일 읽기 예제

예제 코드와 결과는 다음과 같습니다. pd.read_excel() 함수는 pandas.core.frame.DataFrame 자료형으로 반환합니다. 샘플 파일은 아래 파일 링크 또는 GitHub 링크(Raw)에 있습니다. 아래 테스트 코드도 동일한 GitHub 링크에 올라가 있습니다.
import pandas as pd
# excel 파일 읽기
df1 = pd.read_excel('./Grade_Sample.xlsx', sheet_name='Sheet1')
# url에서 excel 읽기
df = pd.read_excel('https://raw.githubusercontent.com/kibua20/devDocs/master/pandas_example/Grade_Sample.xlsx')
print (type(df))
print (df)

Pandas에서 CSV 파일 읽기와 저장
Pandas에서 read_csv()함수를 사용해서 CSV 파일을 Dataframe으로 변환할 수 있습니다. filepath는 로컬 파일뿐 아니라 URL도 지원하며, 각 항목의 구분가 기본값으로는 comma(,)로 설정되어 있으며, tab (\t)나 특정 기호 (e.g. : 표시)를 지정할 수 있습니다. index column이 있는 경우 index_col을 통해서 지정 가능합니다. 실제로는 매우 다양한 설정 옵션이 있으며, 입력 CSV 파일에 따라서 지정할 수 있습니다.

#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import pandas as pd
# csv file에서 읽기
df = pd.read_csv('./copy_grade_sample.csv')
# url에서 csv 읽기
df = pd.read_csv('https://raw.githubusercontent.com/kibua20/devDocs/master/pandas_example/Grade_Sample.csv')
# csv file로 저장
print ('Write to csv')
df.to_csv('copy_grade_sample.csv', index=False, encoding='utf-8-sig')
Pandas에서 csv파일 저장은 df.to_csv() 파일을 사용할 수 있고, Index column의 저장 여부를 index 값을 통해서 설정할 수 있습니다. CSV에 한글이 포함되어 있는 경우 encoding type을 'utf-8-sig'로 설정하여 한글 깨짐 또는 유니코드 깨지는 현상을 방지할 수 있습니다.
관련 글:
[SW 개발/Python] - Python 정규식(Regular Expression) re 모듈 사용법 및 예제
[SW 개발/Python] - Python: JSON 개념과 json 모듈 사용법
[SW 개발/Python] - Python으로 개행 문자(\n)가 포함된 JSON 읽기: JSONDecodeError 수정하기
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Panda Dataframe 날짜 기준으로 데이터 조회 및 처리하기
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Pandas Dataframe 여러 열과 행에 apply() 함수 적용 (Sample code 포함)
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - CSV 파일에서 MariaDB(또는 MySQL)로 데이터 가져오는 방법
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - MariaDB의 Python Connector 설치와 사용 방법
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Jupyter Notebook의 업그레이드: Jupyter Lab 설치 및 extension 사용법
댓글