Padas Dataframe apply() 함수 사용법
Panda dataframe을 엑셀의 매크로 함수처럼 각 열에 대한 연산을 하는 방법입니다. Pandas의 apply()를 사용하고 이는 가장 많이 사용하고 강력한 기능입니다. 각 항목을 요약하면 아래와 같습니다. 본 포스팅에서 설명한 내용은 Github에 test code를 올렸놨습니다.
- 기존의 Column 값을 연산하여 신규 Column을 추가하는 경우: df.apply(func, axis =1) axis=0은 row이고, axis=1은 column입니다.
- Row 값을 추가하는 경우에는 df.loc[] = df.apply(func, axis =0)으로 추가합니다.
- Column과 Row은 바꾸는 경우 df.transpose() 함수를 사용합니다.
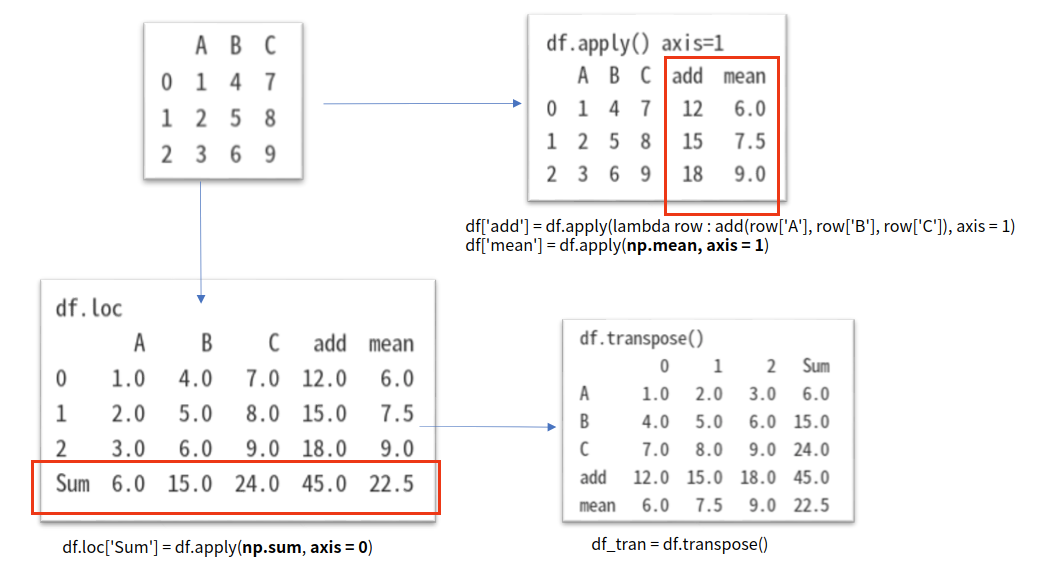
import pandas as pd
import numpy as np
data = {'A':[1, 2, 3], 'B':[4, 5, 6], 'C':[7, 8, 9] }
df = pd.DataFrame(data)
→ 실행 결과: Column A, B, C로 구성되어 있고, Row index는 자동 값으로 0, 1,2 값으로 지정된 상태입니다.

df['add'] = df.apply(lambda row : add(row['A'], row['B'], row['C']), axis = 1)
df['mean'] = df.apply(np.mean, axis = 1)
→ 실행 결과: add column과 mean column을 apply(func, axis=1)으로 추가한 상태입니다.

df2 = df.apply(np.sum, axis = 0)
→ 실행 결과: column 값의 각 값을 함수(sum)으로 처리해서 새로운 dataframe을 생성한 상태

df.loc['Sum'] = df.apply(np.sum, axis = 0)
→ 실행 결과: Sum Row을 추가한 상태입니다. axis=0 으로 설정하고 np.sum() 함수를 적용한 것입니다.

print(df['B'][1],'\n')
→ 실행 결과 (B행 2열)값을 얻어오는 방법 입니다.

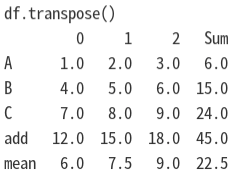
df_tran = df.transpose()
→ 실행 결과: Column과 Row를 각각 전치 행렬로 변환한 것입니다.
Pandas API reference에서는 아래와 같이 정의하고 있습니다.
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
func function: Function to apply to each column or row.
axis: default 0, Axis along which the function is applied:
- 0 or ‘index’: apply function to each column.
- 1 or ‘columns’: apply function to each row.
raw: default False, Determines if row or column is passed as a Series or ndarray object:
- False : passes each row or column as a Series to the function.
- True : the passed function will receive ndarray objects instead. If you are just applying a NumPy reduction function this will achieve much better performance.
result_type{‘expand’, ‘reduce’, ‘broadcast’, None}, default None These only act when axis=1 (columns):
- ‘expand’ : list-like results will be turned into columns.
- ‘reduce’ : returns a Series if possible rather than expanding list-like results. This is the opposite of ‘expand’.
- ‘broadcast’ : results will be broadcast to the original shape of the DataFrame, the original index and columns will be retained.
Pandas Dataframe Apply() 사용해서 기존 Dataframe에 새로운 2개 이상의 column 추가
Dataframe.apply()를 사용해서 기존 DataFrame에서 새로운 column 추가하는 방법입니다. 여기서 주의해야 할 것은 function의 return은 tuple이나 list형으로 반환하고, apply() 값을 새로운 column의 list로 받아야 합니다.

실제 코드 예제는 아래와 같습니다. 이과정에서 result_type을 반드시 'expand' 형으로 설정해야 합니다. result_type을 설정하지 않는 경우 "Must have equal len keys and value when setting with an iterable" 에러가 발생합니다. 보다 간편한 방법으로 'add'와 'mutiply' 함수 인자에 dataframe의 입력 값을 직접 넣어서 각각의 column을 추가도 가능합니다.
def add_multiply (a,b):
# tuple 또는 list로 return
return a+b, a*b
# 방법1. 'add'와 'multiply' column 추가 add = a+b , multiply = a × c
df[['add', 'multiply']] = df.apply(lambda x: add_multiply(x['A'], x['B']), axis=1, result_type='expand')
#방법2. 'add'와 'mutiply' 함수 인자에 dataframe의 입력 값을 직접 넣어서 각각의 column을 추가도 가능
df['add'], df['multiply'] = add_multiply(df['A'],df['B'])
에러 메시지:
Traceback (most recent call last):
File "dataframe_to_json_test.py", line 75, in <module>
test4()
File "dataframe_to_json_test.py", line 68, in test4
df[['add', 'multiply']] = df.apply(lambda x: add_multiply(x['A'], x['B']), axis=1)
File "/usr/local/lib/python3.8/dist-packages/pandas/core/frame.py", line 3160, in __setitem__
self._setitem_array(key, value)
File "/usr/local/lib/python3.8/dist-packages/pandas/core/frame.py", line 3198, in _setitem_array
self.iloc[:, indexer] = value
File "/usr/local/lib/python3.8/dist-packages/pandas/core/indexing.py", line 692, in __setitem__
iloc._setitem_with_indexer(indexer, value, self.name)
File "/usr/local/lib/python3.8/dist-packages/pandas/core/indexing.py", line 1635, in _setitem_with_indexer
self._setitem_with_indexer_split_path(indexer, value, name)
File "/usr/local/lib/python3.8/dist-packages
/pandas/core/indexing.py", line 1711, in _setitem_with_indexer_split_path
raise ValueError(
ValueError: Must have equal len keys and value when setting with an iterable
관련 글:
[SW 개발/Python] - Python: JSON 개념과 json 모듈 사용법
[SW 개발/REST API] - 자주 사용하는 curl 명령어 옵션과 예제
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - MariaDB의 Python Connector 설치와 사용 방법
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - CSV 파일에서 MariaDB(또는 MySQL)로 데이터 가져오는 방법
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - MariaDB 또는 MySQL에서 사용하는 Data type 정리
댓글