앞서 설명한 선형 회귀(Linear Regression)는 다중회귀(Multiple Regression) 분석은 독립 변수가 2개 이상의 회귀 모형을 분석 대상으로 삼고 있습니다. 이를 그림으로 표현하면 아래와 같습니다. Y= aX+b 모델에서 독립변수 X의 개수가 증가하고, 이를 Table로 표현하면 독립 변수의 Column의 개수가 증가하는 것입니다.
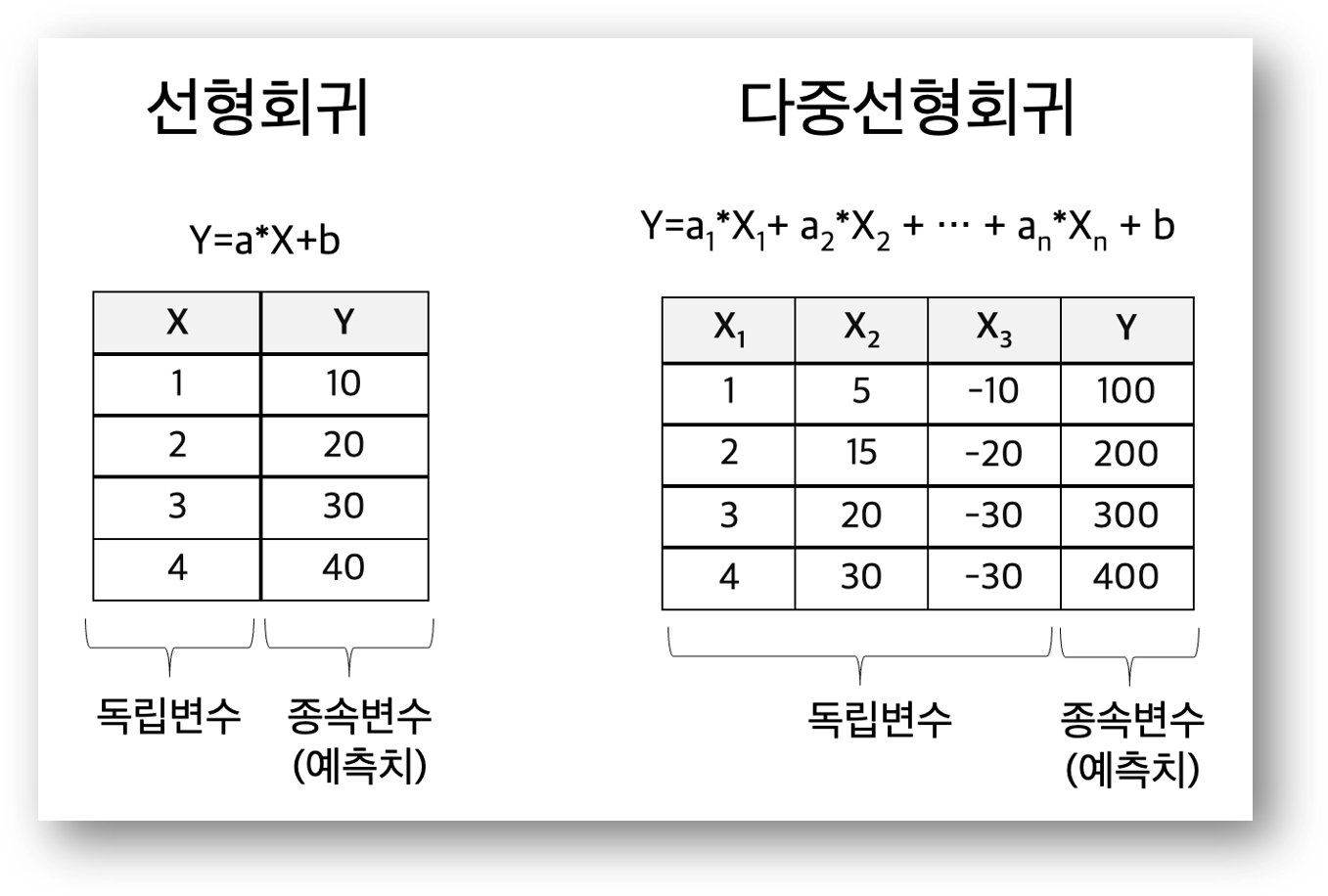
Keras에서 선형회귀 분석에 대한 설명은 아래 포스팅을 확인 부탁드립니다. 본 포스팅에서는 선형 회귀에서 다중회귀에서 변경해야 하는 부분을 설명하고자 합니다.
다중회귀에서 변경해야 하는 부분
Python Keras 는 ① Data set 구성, ② Keras Model과 Layer 정의 , ③ Model compile, ④ Model Fit, ⑤ Prediction 과정으로 구성됩니다. 이 과정 중에서 ① Data set 구성, ② Keras Model과 Layer는 입력 데이터에 맞게 변경하고, 이후 과정을 Linear regression과 동일하게 유지합니다. ① Data set은 주어진 입력 값을 numpy arrary이 pandas dataframe 형식으로 입력합니다. ② Keras Model과 Layer는 Dense의 output dim 값은 1 개 이기 때문에 '1'을 그대로 입력하고, 입력 값 (독립 변수)는 1개에서 3개로 증가하였기 때문에 'input_dim=3'으로 입력합니다.

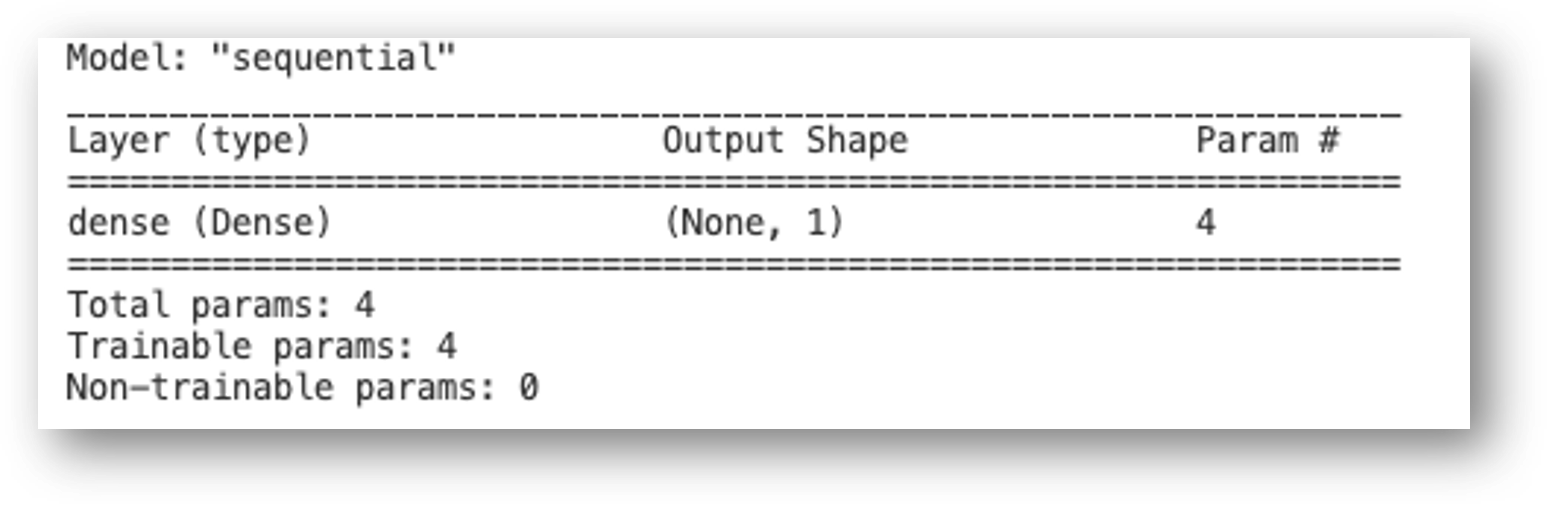
Model summary 확인
model.summary() 함수로 확인하면 아래와 같습니다. Output shape은 Linear regression과 동일하고 Training parameter가 4개로 (X1, X2, X3, constant) 증가했음 알 수 있습니다.
Model Traing Evalution: MSE (Mean of Squre error)가 큼
Model의 Training 결과를 확인하면 1번째 training에서 MSE (Mean Squre Error) 값이 아주 큰 값이 나오고, 2번째 epochs부터는 MSE 값이 무한대(inf) 값이 나와 더 이상의 최적 값을 찾지 못하고 에러 값이 발산하고 있고 있습니다.
- Epoch 1/100 6/6 [] - 0s 627us/step - loss: 371998072827503324905735192576.0000 - mse: 371998072827503324905735192576.0000
- Epoch 2/100 6/6 [ ] - 0s 561us/step - loss: inf - mse: inf
- Epoch 3/100 6/6 [] - 0s 410us/step - loss: nan - mse: nan
Learning rate (Hyper parameter) 수정
MSE를 수렴시키기 위해서는 최적화 (optimizer) 방법을 수정해야 합니다. 최적화 알고리즘을 SDG 대신 다신 알고리즘을 사용하던가, SDG는 유지하고 Hyperpameter 인 learing rate(학습률)을 변경해야 합니다. 학습률에 대한 설명은 Google ML(Machine Learing) Developer 사이트에서 잘 설명되어 있고, 요약하면 다음과 같습니다.
- Learning Rate (학습률, Step size)가 너무 작은 경우: 최적 값을 찾아가기 위한 연산 시간이 많이 늘어납니다. epochs 값이 낮은 경우 최적 값을 못 찾을 수도 있습니다.
- Learning Rate이 너무 큰 경우: 최적 값을 skip 할 수 있습니다. Cost 함수가 줄어들다가 다시 증가할 수 있습니다.
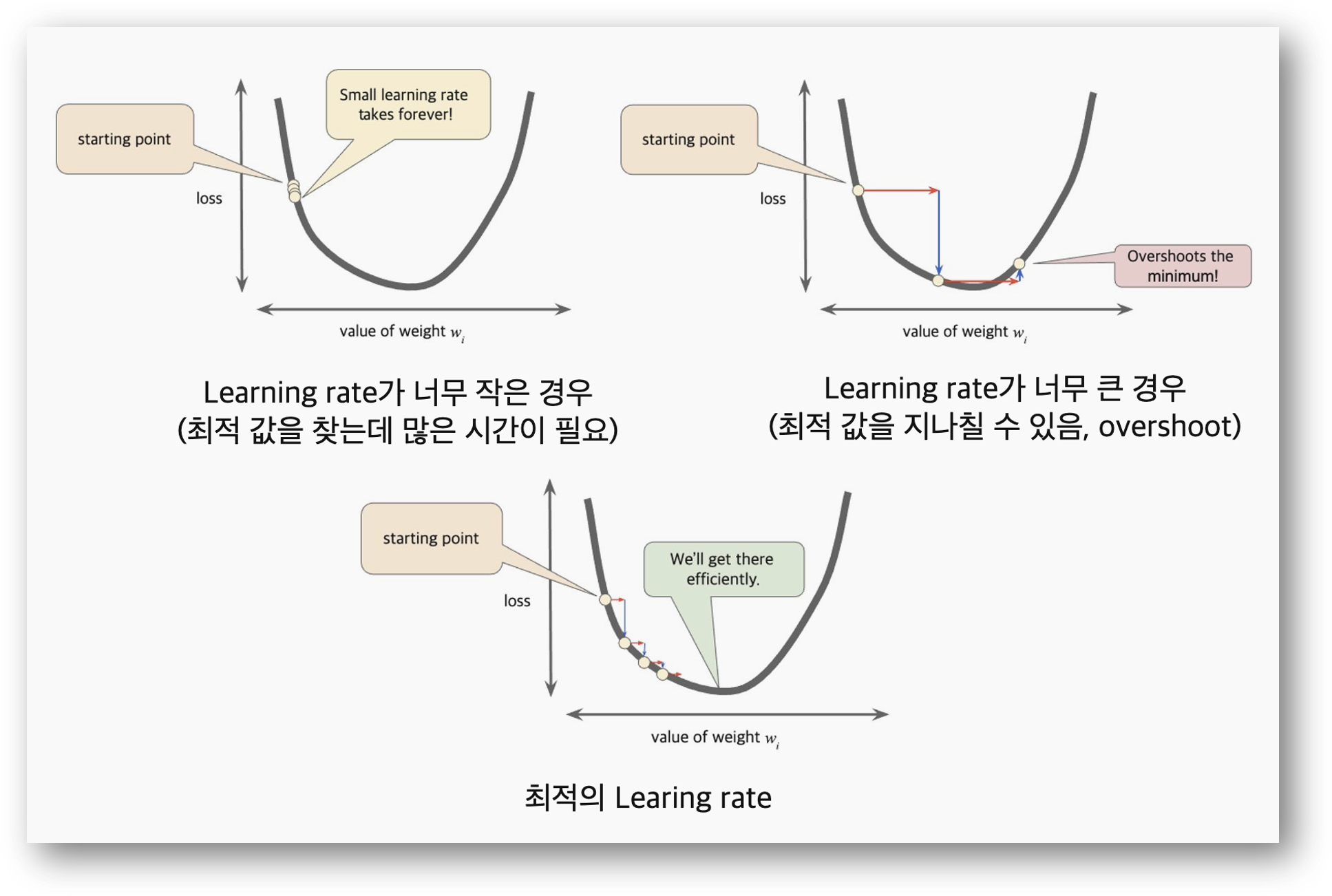
Learning rate은 0.01에서 줄여가면서 반복 테스트하면서 cost funciton인 MSE 값을 확인합니다. optimizer.SDG() 함수에서 learning_rate은 조정합니다.
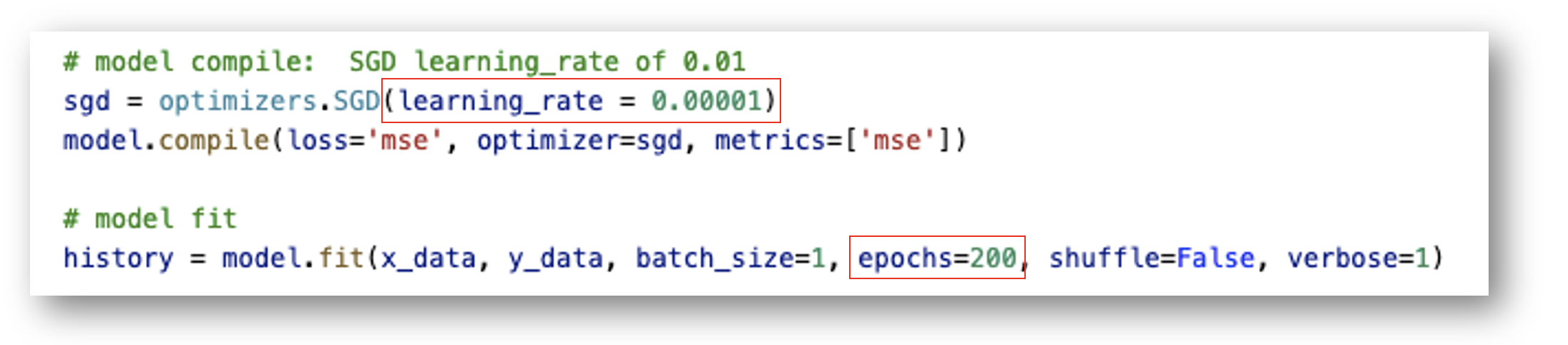
Learing rate에 따른 MSE 값을 확인하면 다음과 같습니다. Learning rate 0.00001에서 최적 값을 찾았습니다.
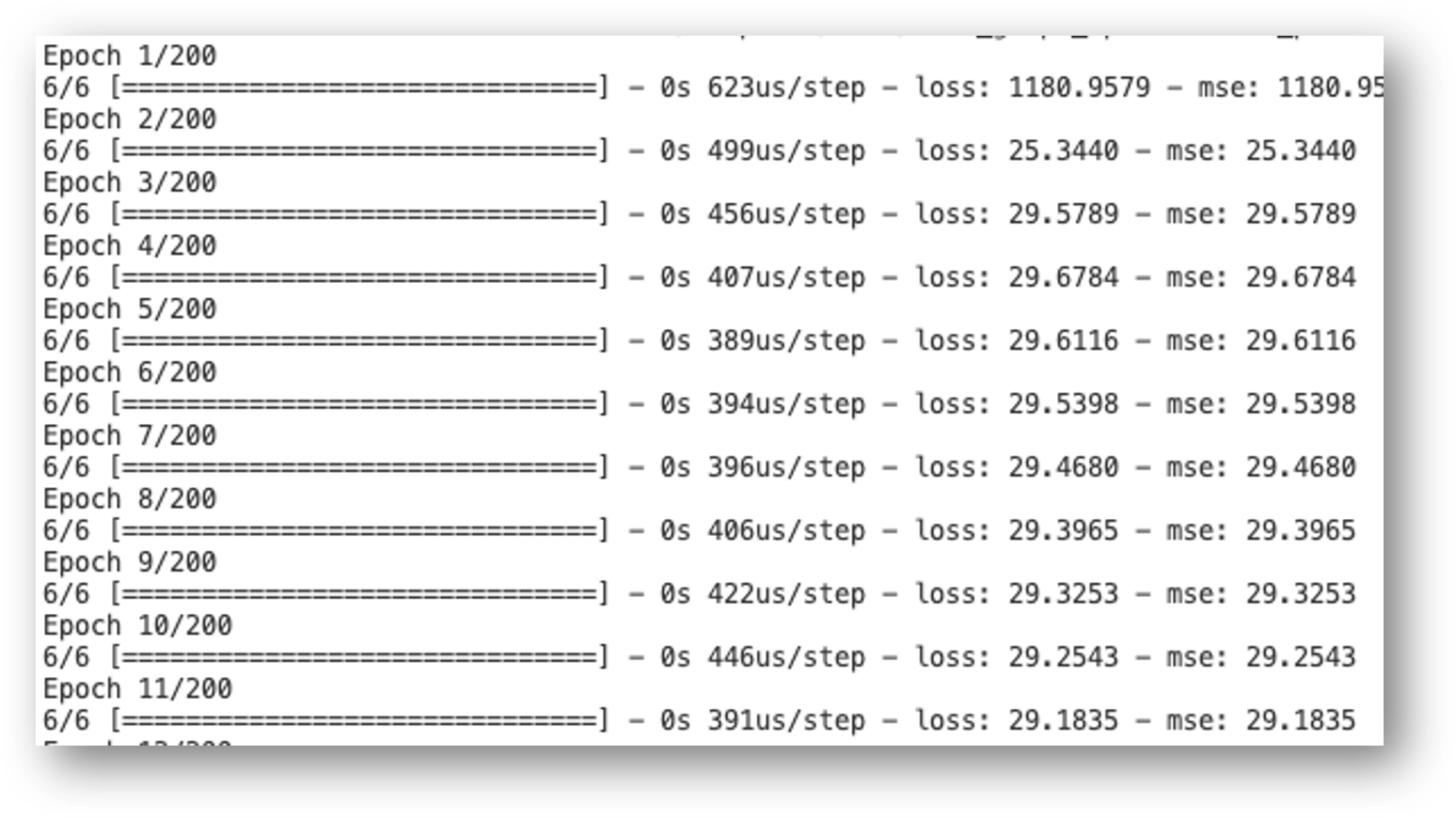
Epochs parameter 조정
Learning Rate을 확인하였다면, Traing의 반복 회수인 Epochs 값을 확인합니다. model.fit() 함수에서 epochs 값을 조정합니다. 현재 200에서 300으로 늘리면 MSE 값이 10.1 값으로 수렴합니다. epochs를 400으로 설정해도 MSE 10.2에서 개선이 미미합니다.
- epochs 200인 경우: MSE = 29.1
- epochs 300인 경우: MSE = 10.1 → epochs 값은 300으로 결정
- epochs 400인 경우: MSE = 10.2

Sample code
앞에서 설명한 Sample code는 GitHub에 올렸고, code는 아래와 같습니다. Sample code 출처는 https://www.edwith.org/pnu-deeplearning/lecture/57302/ 이며, 최신 Keras 버전에서 에러 나는 부분을 수정하고, Graph 생성 부분을 추가하였습니다.
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# from keras.models import Sequential
# from keras.layers import Dense
# from keras import optimizers
import matplotlib.pyplot as plt
# data set
x_data = np.array([
[73,80,75],
[93,88,93],
[89,91,90],
[80,80,80],
[96,98,100],
[73,66,70],
])
y_data = np.array([72,88,92,81,100,71])
# model: linear regression input dense with dim=1
model = Sequential()
# 다중 회귀에서는 input dim 값과, output_dim 값을 변경해야 함.
model.add(Dense(1, input_dim = 3, activation='linear'))
# model compile: SGD learning_rate of 0.01
sgd = optimizers.SGD(learning_rate = 0.00001)
model.compile(loss='mse', optimizer=sgd, metrics=['mse'])
# model fit
history = model.fit(x_data, y_data, batch_size=1, epochs=400, shuffle=False, verbose=1)
# prediction
x_test = np.array([[90,88,93], [70,70,70]])
print (model.predict(x_test))
# print model summary
model.summary()
# 학습 정확성 값과 검증 정확성 값을 플롯팅 합니다.
# print(history.history)
#plt.plot(history.history['accuracy'])
plt.plot(history.history['loss'])
plt.title('Train Loss')
plt.ylabel('Loss')
plt.savefig('tran_result.png')
관련 글:
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Python Keras를 이용한 Linear regression 예측 (Sample code)
[SW 개발/Python] - Python Decorator를 이용한 함수 실행 시간 측정 방법 (Sample code)
[SW 개발/Python] - Python 정규식(Regular Expression) re 모듈 사용법 및 예제
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Python Pandas로 Excel과 CSV 파일 입출력 방법
[SW 개발/Python] - Python: JSON 개념과 json 모듈 사용법
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Pandas Dataframe 여러 열과 행에 apply() 함수 적용 (Sample code 포함)
댓글