Python Panadas의 Dataframe는 기본적으로 각각의 row 또는 column을 순차(squencial) 처리합니다. 데이터의 크기가 증가하면 처리 속도는 기하급수적으로 저하가 있으며, 이는 병렬 처리를 통해서 처리 속도를 향상시킬 수 있습니다. Python 병렬 처리를 지원하는 다양한 라이브러리가 있으며(참고 링크), 본 포스팅에서는 Pandas Dataframe에 특화된 Swifter 모듈 사용법과 테스트 결과를 설명합니다.
Swifter 설치
Swifter는 Python package 매니저인 PyPI로 설치할 수 있습니다. Swifter 설치 시 dask, bleach 등 관련 모듈도 같이 설치됩니다.
Swifter 사용법
Swifter Github 문서(https://github.com/jmcarpenter2/swifter/blob/master/docs/documentation.md)에 사용법이 설명되어 있습니다. 사용법은 import swifter 후에 df.apply() 함수를 df.switfer.apply()로 변경하고, 함수 parameter는 기존과 동일하게 유지합니다. Swifter 사용법에 대한 예제는 다음과 같고, 기존 Python code에서 변경이 필요한 부분은 붉은 색으로 강조했습니다.
import pandas as pd
import swifter
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func, positional_arg, keyword_arg=keyword_argval)
Switfter 적용 전/후의 실험 결과
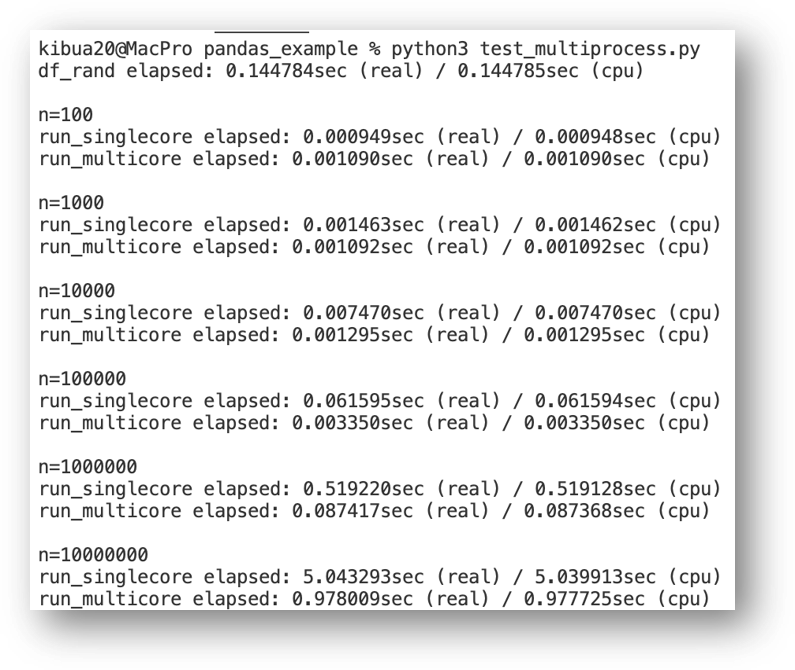
Swifter 적용 전/후의 결과를 확인하기 위해서 10,000,000 개 row와 column 'x'를 가지는 dataframe df를 생성하고, 메모리 상에서 n개의 sample을 추출해서 동일한 연산(=제곱)을 적용해서 column 'x2'을 추가합니다. Singlecore (즉, 하나의 thread만 사용하는) df.apply() 함수와 멀티 코어의 df.swifter.apply() 함수의 측정 시간을 비교하였습니다. 측정 시간은 decorator (@elasped) 기능을 사용하였고, 이에 대한 내용은 별도로 포스팅 예정입니다. Random number를 가지는 DataFrame 생성은 링크를 참조해주세요.
측정을 위한 전체 테스트 코드는 아래와 같고 GitHub에도 반영했습니다.
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import pandas as pd
import swifter
import numpy as np
import time
def elapsed(f):
def wrap(*args):
start_r = time.perf_counter()
start_p = time.process_time()
ret = f(*args)
end_r = time.perf_counter()
end_p = time.process_time()
elapsed_r = end_r - start_r
elapsed_p = end_p - start_p
print(f'{f.__name__} elapsed: {elapsed_r:.6f}sec (real) / {elapsed_p:.6f}sec (cpu)')
return ret
return wrap
@elapsed
def df_rand(row_size):
df = pd.DataFrame(np.random.randint(0,row_size,size=(row_size, 1)), columns=['x'])
# # 빈 DataFrame 생성하기
# df = pd.DataFrame(columns=['idx', 'x'])
# for idx in range(1, row_size):
# # 1과 size 사이의 random 한 값 생성하기
# number = random.randint(1, row_size)
# # DataFrame에 특정 정보를 이용하여 data 채우기
# df = df.append({'idx':idx, 'x':number}, ignore_index=True)
# df.set_index('idx', inplace=True)
return df
@elapsed
def run_singlecore(df):
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
@elapsed
def run_multicore(df):
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
# df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
# df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
# df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func,positional_arg, keyword_arg=keyword_argval)
if __name__ == '__main__':
# df = df_rand(100)
# print (df)
# exit(0)
df = df_rand(10000000+1)
print ('\nn=100')
df_sample = df.sample(n=100)
run_singlecore(df_sample)
run_multicore (df_sample)
print ('\nn=1000')
df_sample = df.sample(n=1000)
run_singlecore(df_sample)
run_multicore (df_sample)
print ('\nn=10000')
df_sample = df.sample(n=10000)
run_singlecore(df_sample)
run_multicore (df_sample)
print ('\nn=100000')
df_sample = df.sample(n=100000)
run_singlecore(df_sample)
run_multicore (df_sample)
print ('\nn=1000000')
df_sample = df.sample(n=1000000)
run_singlecore(df_sample)
run_multicore (df_sample)
print ('\nn=10000000')
df_sample = df.sample(n=10000000)
run_singlecore(df_sample)
run_multicore (df_sample)
Swifter 성능 측정 결과
성능 측정에 사용된 노트북은 2.6 GHz, 6 core, Intel Core i7 CPU와 16GB 2667Hz DDR4 RAM의 MacBookPro 2019입니다. 측정 결과 ➊ 전반적으로 Swifter를 적용한 Dataframe의 연산 결과가 singlecore 연산보다 더 빠름을 알 수 있고, ➋ Dataframe의 크기가 클수록 데 연산 속도 차이는 더 커지며 swifter의 성능이 우수함을 알 수 있습니다. Sample size n=100과 n=1000에서는 1ms 이하의 매우 작은 차이지만, Sample size n=10,000,000인 경우 기존 single core 연산은 5.04 sec, swifter는 0.97 sec으로 대략 5배 정도의 성능 개선이 가능합니다.
또한 Swifter GitHub에 공개한 측정 결과를 확인해보면 row의 개수가 1,000 이상이면 성능의 차이가 발생하기 시작하고, Dask 병렬 처리보다 Swifter가 우수한 결과를 보여주고 있습니다.

관련 글:
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Python Pandas로 Excel과 CSV 파일 입출력 방법
[SW 개발/Python] - Python 정규식(Regular Expression) re 모듈 사용법 및 예제
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - Panda Dataframe 날짜 기준으로 데이터 조회 및 처리하기
[SW 개발/Data 분석 (RDB, NoSQL, Dataframe)] - CSV 파일에서 MariaDB(또는 MySQL)로 데이터 가져오는 방법
[개발환경/우분투] - 대용량 파일을 작은 크기로 분할하는 방법: split
[SW 개발/Python] - Python 음수 인덱스: line.split('+')[-1] 또는 line.split('/')[-1] 의미
댓글